
Yıllar boyunca artan verinin Relational DB’lerde artık saklanamaz boyuta erişmesinden ötürü -ki bunlar sosyal medya paylaşımları, ağ günlükleri, bloglar, fotoğraf, video, log dosyaları vs gibi değişik kaynaklardan toparlanan veriler- anlamlı ve işlenebilir biçime dönüştürülmüş biçimine Big Data denir. Her ne kadar kimilerince bilgi çöplüğü diye de tabir edilen bu kavram ile verinin öneminin ve değerinin her geçen gün artmakta olması bu çöplükten! muazzam derecede önemli, kullanılabilir bilgilerin elde edilmesi amacıdır.
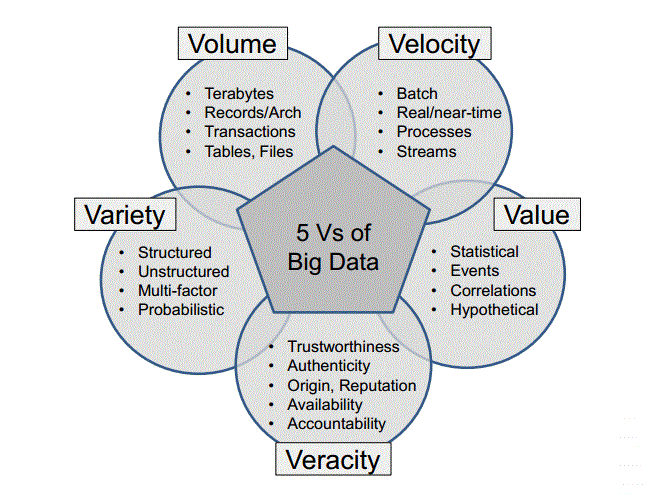
Big Data kavramını daha yakından ele alıcak olursak oluşumundaki bileşenleri incelemek gerekir. Bunlar; variety, velocity, volume, verification ve value ‘dur.
- Variety (Çeşitlilik): Üretilen verinin yüzde 80’i yapısal değil ve her yeni üretilen teknoloji, farklı formatlarda veri üretebiliyor. Telefonlardan, tabletlerden, bütünleşik devrelerden gelen türlü çeşitlilikte “Veri Tipi” ile uğraşılması gerekiyor. Bir de bu verilerin farklı dillerde, Non-Unicode olabileceğini düşünürseniz, bütünleşik olmaları, birbirlerine dönüşmeleri de gerekli.
- Velocity (Hız): Big Data’nın üretilme hızı çok yüksek ve gittikçe artıyor. Daha hızlı üreyen veri, o veriye muhtaç olan işlem sayısının ve çeşitliliğinin de aynı hızda artması sonucunu doğuruyor.
- Volume (Veri Büyüklüğü): IDC istatistiklerine göre 2020’de ulaşılacak veri miktarı, 2009’un 44 katı olacak. Şu anda kullanılan, “büyük” diye adlandırdığımız kapasiteleri ve “büyük sistemleri” düşünüp, bunların 44 kat büyüklükte verilerle nasıl başa çıkacaklarını hayal etmek gerekiyor! Kurumun veri arşivleme, işleme, bütünleştirme, saklama vb teknolojilerinin bu büyüklükte veri hacmi ile nasıl başa çıkacağının kurgulanması gerekiyor. 2010’lu yıllarda dünyadaki toplam bilişim harcamaları yılda %5 artmakta, ancak üretine veri miktarı %40 artmaktadır.
- Verification (Doğrulama): Bu bilgi yoğunluğu içinde verinin akışı sırasında “güvenli” olması da bir diğer bileşen. Akış sırasında, doğru katmadan, olması gerektiği güvenlik seviyesinde izlenmesi, doğru kişiler tarafından görünebilir veya gizli kalması gerekiyor.
- Value (Değer): En önemli bileşen ise değer yaratması. Bütün yukarıdaki eforlarla tariflenen Big Data’nın veri üretim ve işleme katmanlarından sonra kurum için bir artı değer yaratıyor olması lazım. Karar veriş süreçlerinize anlık olarak etki etmesi, doğru kararı vermenizde hemen elinizin altında olması gerekiyor. Örneğin sağlık konusunda stratejik kararlar alan bir devlet kurumu anlık olarak bölge, il, ilçe vb detaylarda hastalık, ilaç, doktor dağılımlarını görebilmeli. Hava Kuvvetleri, bütün uçucu envanterindeki taşıtlarının anlık yerlerini ve durumlarını görebilmeli, geriye dönük bakım tarihçelerini izleyebilmeli. Bir banka, kredi vereceği kişinin, sadece demografik bilgilerini değil, yemek yeme, tatil yapma alışkanlıklarını dahi izleyebilmeli, gerekirse sosyal ağlarda ne yaptığını görebilmeli.
Peki nedir bildiğimiz Relational DB’den farkı?
Relational DB’de veri bütünlüğü (Atomicity, Consistency, Isolation, Durability) dikkate alınarak çalışıldığı için Big Data çözümlerine göre çok daha yavaş çözümlerdir. Ayrıca relational DB’de gigabyte seviyelerinde işlem yapılırken Big Data ile petabyte seviyelerinde veri tutulmaktadır. Big Data çözümleri, dağıtık dosya sistemine* göre çalıştığı için veri bütünlüğü kuralları geçerli değildir. İlişkisel veritabanlarındaki gibi bir tablo yapısı olmadığı için veriler bütünleşik (denormalize) olarak saklanmaktadır. Çünkü büyük verinin tutarlılık (Consistency), müsaitlik (Availability) ve parçalanma payı (Partition tolerance) kurallarının hepsini sağlaması mümkün olmadığından bir kaç tane verinin doğru olmaması ya da kaybolması, veri büyüklüğünü dikkat aldığımızda önemli değildir. Bu nedenle, büyük veriyi dikey ölçeklemeyle çok pahalı olarak saklamak yerine, basit donanımların dağıtık dosya sistemleri ile birleşimi sonucu çok ucuza saklama yöntemi, büyük veri çözümlerini (NoSQL, Hadoop vs.) doğurmuştur. Bu veri çözümlerinden günümüzde en çok bilinenleri NoSQL – not only sql- çözümleridir. NoSQL çözümlerinin hepsinin farklı bir amacı vardır. Bu nedenle direk karşılaştırmak doğru bir yöntem değildir, kullanacağınız amaca göre kendinize uygun olanı seçmelisiniz. Örneğin; MongoDB az veri ekleme çok veri okuma işlemi için uygun iken, Redis çok yazma, çok okuma olan ve veri kaybının geri planda olduğu bir sistem için tercih edilmelidir, Hadoop ise çok çok büyük veri ile kısa sürede işlem yapmanız gerektiğinde kullanılmalıdır.
*Eric Brewer tarafından 2000 yılında ortaya atılan, dağıtık (distributed) sistemlerin aynı anda, Consistency (tutarlılık : dağıtık sisteme bağlı tüm node’larda aynı verilerin olması), Availability (kullanılabilirlik : tüm isteklere her zaman cevap verilebilmesi) ve Partition Tolerance (parça teloransı : sistem parçalarından birinin çalışmaması durumunda sistemin düzgün devam etmesi) özelliklerini sağlayamayacağı savunduğu teorisi
